This essay is about some of what makes me excited about a project like MusicBrainz. Even though in many ways it superficially resembles other similar projects, such as IMDb or All Music Guide, it also represents the cusp of a new wave of joined-up internet applications which much more efficiently connect people to the information they're looking for.
MusicBrainz is a project designed to build an online music database, covering artists, albums and songs. Information is stored about which artists released which albums, when and in what countries. What songs were on the album. Who else has recorded those songs. Which people played what instruments on the songs. Which bands were they part of, and for how long. And so on and so on. The information is contributed by a large community of users. Anyone with internet access is invited to edit the database directly, contributing their own knowledge of the world of music.
This information is already online. The difference is that this information is scattered all over thousands of webpages, with little if any common formatting or structure. MusicBrainz attempts to bring this information together in one place and give it a single, consistent user interface. Thus, if at any time you're listening to a song on the radio and you're thinking "wow, that's pretty good, I wonder what album it's from?", you know you can quickly find the answer on MusicBrainz. And the album won't be described in the middle of ten screenfulls of additional text about how it revolutionised the blogger's life cause that's how they met their boyfriend and OMG he's so cute and here's photos of us on holiday in Ibiza. The information that is displayed is just the raw facts that the user is after.
Online databases like this represent a big improvement over the "big mess of pages that you can google through" that is the current model of the World Wide Web. Google is a powerful tool, and constantly improving. But different jobs require different tools. Google is trying to provide a really clever tool that can do any job at all, and the result is inevitably rather inefficient. There's a fundamental difference between searching for the text '"album" + "Easy"' and searching for the album called "Easy". Google allows you to do the former, but MusicBrainz allows you to do the latter.
The MusicBrainz database is already quite complicated, and it's being continually updated. There are specialised ways of representing artists who have guest appearances on a track. Or on an album. You can say that they were the guitarist, the remixer, the symphony orchestra that played in the background, the producer, the guy who did the artwork for the album cover... the list goes on and on.
All of this complexity has a cost in terms of usability of the site. More and more data needs to be crammed into a page layout that has to look good and work intuitively for every artist from Elvis Presley to Vanilla Ice to the London Symphony Orchestra. Sooner or later the strain is going to show.
To fight against this, MusicBrainz needs to choose its data carefully. It can't possibly represent every credit that's printed in the liner notes on every album. It needs to select what pieces of data are really useful to its users, and ensure that the data model encourages the database to be enriched, not overloaded. In IT terms, it needs to guard against feature creep.
This, unfortunately, tends to cause conflict. The MusicBrainz users are people who love their music and want the world to know all about it. The more data they can add the happier they are. The MusicBrainz users' list frequently features requests for an expansion of the database: catalog numbers, artist's familial relationships, BWV numbers. All kinds of bits and pieces that would be really really useful. Keeping the MusicBrainz system usable means having to say no to these requests, and that makes people unhappy.
I've worked on traditional, in-house databases before, and the compromises you have to make can really hurt sometimes. Much of the time it feels like you're just throwing data away for no good reason. With a community database like MusicBrainz, where people aren't even getting paid for adding this data, this is an even more bitter pill to swallow.
A good example of this is the tension between classical music and pop music. The MusicBrainz database revolves around relationships between three basic entities: artists, albums, and tracks. But already this is clearly biased towards pop music. Albums and tracks didn't exist until the 20th century. Classical music revolves around composers, works and performances. It has a completely different structure that just cannot be shoehorned into a pop music data model.
Not that people don't try. There are elaborate rules about whether the primary artist is the composer or the performer, and how to represent each track as a component of a larger work. It sorta kinda works, but it leaves most users with a bad taste in their mouth.
There are various proposals to make MusicBrainz more suitable for classical music. But ultimately any such implementation will have to present two completely different data models on the same set of pages. The cost will be greatly increased complexity, and a much harder to use website. People who want to add pop albums will be confused by all the classical-oriented options, and people who want to add classical works will be confused by all the pop-music-oriented options. The compromises are going to really hurt, and it's easy to imagine a pop-music oriented camp of users ending up bitterly opposed to a classical-music oriented camp of users. This is where things start to get ugly.
In a traditional, proprietary database, the answer is simple: we compromise where we can, throw out data where we can't, and the designers and the users just like it or lump it. This is how allmusic.com works.
In a traditional open source software project, when the compromises get too much to bear, the usual result is a "fork". Those developers who can't stand the direction the project is going make a big copy of everything that's been developed so far, and use it to found a new project. Over time the two projects end up serving completely different purposes: and yet they each inherit software that was designed as a compromise. In addition to splitting the resources of the open source community, the two sets of developers end up having to work from a software base that doesn't really meet their needs. In the open source community, project forks are usually seen as a terrible waste.
For an open database like MusicBrainz, however, there's potential for a better solution. Classical purists can still storm off and found a new project, but they don't have to leave the old project behind. OK, so MusicBrainz isn't a good way to represent classical works: but it's still a great way to represent albums, and classical music sometimes comes on albums. The new ClassicalBrainz project therefore doesn't have to have a database of albums. They have their own database of composers, conductors, orchestras, works and performances; but any time a performance happened to be recorded and sold, they simply link to the corresponding MusicBrainz entry. Thus the problem of representing CDs, LPs, re-issues, remasters, track lengths, and so on, all stays as MusicBrainz's responsibility. Any new features MusicBrainz implements will be available to ClassicalBrainz automatically.
Meanwhile, MusicBrainz benefits from having access to much richer information about classical music than would ever fit in their own database. Classical albums simply link to the corresponding entry of ClassicalBrainz. Users don't care about where the data is hosted; they just see a richer information store than they ever had access to before.
The feature that I've regularly asked for on the MusicBrainz lists is the addition of barcodes. Barcodes are a world-wide industry standard identifier for almost every product available; especially music. Using a barcode enables both people and businesses to know precisely what they're buying and selling. Many businesses base their entire databases around barcodes: you don't sell a "CD player", you sell a "72286846232". These businesses could make great use of the MusicBrainz data, and they have every right to use it how they want; they just can't figure out what products the database is talking about.
The problem is that adding barcodes would, however incrementally, add complexity to the database and to the user interface. You have to ask yourself, does this data really belong in MusicBrainz? And the more I think about it, the more I think the answer is clearly "no".
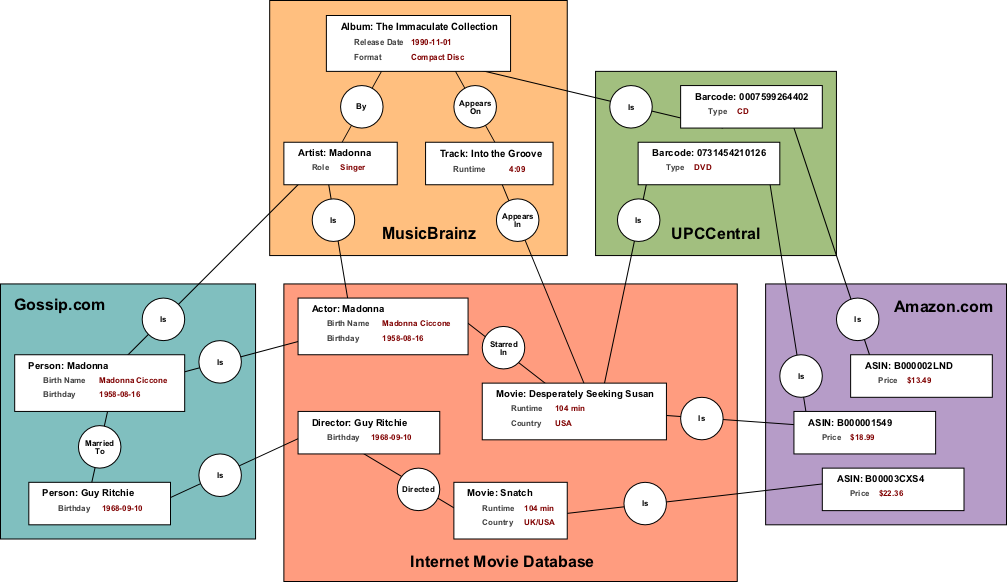
Barcodes are unique identifiers for products, not music. There are a lot of products in the world, and only a tiny fraction of them are music. So instead of building a database of music barcodes, why don't we just build a database of barcodes, full stop? Let's say we call it "UPCCentral". Give it a simple structure and a user interface that allows people to add information about products. Then add links to other online databases that have more information about them.
Thus, if the product happens to be a CD, allow users to add the MusicBrainz ID of the album. People who stumble across the CD on the UPCCentral site can click on a link to call up a full listing of who the artist was, how many tracks there are and what they're called, and so on.
On the other hand, if the product happens to be a DVD, allow users to add the Internet Movie Database (IMDb) ID of the movie. Then people can click on a link to call up the plot summary, list of actors, and a wealth of other information.
What's more, Amazon.com understands barcodes. So once you find a product on UPCCentral or one of its related sites, you can buy it from Amazon without having to look it up.
Any number of other websites could be added in the same way. The very existence of a barcode database could encourage them to form. Maybe a database of consumer electronics gadgets, including detailed descriptions and links to related accessories. Maybe a list of grocery items, including their nutritional content and links to recipes. Maybe a generalised review engine: a website dedicated to allowing users to contribute reviews, of any product at all, be it a luxury car or a can of baked beans.
Not that barcodes are the glue that holds everything together. Databases have other links as well. For example, MusicBrainz currently has the facility to record some basic information about relationships between artists: X is the sister of Y, or W is married to Z. But this facility is pretty limited, and it's debatable whether it has anything to do with music at all.
Why not have a celebrity gossip database? A website dedicated to recording not only who's married to who or who's related to who; but who's been seen about town with who, who is having a public feud with who, who's been arrested with who and why. Allow users to add not only their MusicBrainz artist IDs, but also their IMDb IDs. This would simplify MusicBrainz, and at the same time enrich whatever other databases touch on the subject. Everything is linked together, and users can seamlessly navigate from one database schema to another without ever having to be aware that they've crossed a boundary.
This approach enables online databases to concentrate on one small, well defined area, and make sure they do it right. They can escape pressure from users to expand the database in new directions. MusicBrainz concentrates on music: not celebrity gossip (relationships between musicians), not marketing or distribution (barcodes and release dates), and not visual art (album covers and music videos). This simultaneously makes online databases cleaner and easier to use, and lowers the bar for new online databases that have something to contribute. An online database that collects the sodium content of tinned spaghetti brands might not seem the most enticing proposition in the world; but if the data gets linked to by another, established online database, it could find itself with millions of users literally overnight.
Hypertext links, of course, suck. Just because there's a link, doesn't mean the data at the other end is accessible. And even if it is there, it might have completely different content to what the author thought it had when they set up the link. Browsing the internet is frequently a frustrating experience.
MusicBrainz is currently acquiring links to Amazon detail pages for albums, and it shows many of the flaws of this approach. The list is updated once every so often, which means the link at the other end isn't always guaranteed to be there. And because the matching is done fuzzily on the name of the album, not on something more stable like a barcode, the album at the other end isn't necessarily what you were after. Finally, MusicBrainz has to store all the URLs for all the albums in a big table, which adds extra complexity to MusicBrainz's system.
There's a better approach to this problem than trying to replicate someone else's database: use their database. A web service is rather like a website designed for computers to use instead of humans. The computer types the information it wants to look up into a form, and the results are returned over HTTP, just like a web page. But the results are greatly simplified, and much more structured, so the computer can take the results, reformat them, perform further computations with them, and display the results to the end user in a way that makes sense for the particular application.
So let's imagine that the network in the diagram above has been implemented, and a MusicBrainz user has landed on the page for the Madonna album "The Immaculate Collection". MusicBrainz wants to know the URL of Amazon's cover art. To get this, it first asks UPCCentral for the barcode, using MusicBrainz's own identifier for that album ("1b1684df-62c4-4efe-a0f0-59049e1f747a") as the search term. UPCCentral returns the barcode, "0007599264402". Next, MusicBrainz uses Amazon's web services to ask for the cover art URL, using "0007599264402" as the search term. Amazon returns the URL, and the image is returned to the user on MusicBrainz's album page. The image also forms a link that will take the user to Amazon's page for the album, so they can buy it.
Unlike regular hard-wired links, this information is all compiled in real time. Only the most up-to-date information recorded in UPCCentral and Amazon is returned. Neither the barcode nor the cover art is stored in MusicBrainz's database. Effectively MusicBrainz gets the full complexity of those two organisations' databases for free. This is a very good deal!
This "new" kind of network has a name: the Semantic Web. The name refers to giving "meaning" to the web - particularly meaning for machines. At the moment the web has meaning for humans, but that means that humans have to drive. If the web becomes readable for machines, then machines can do the hard slog of browsing around the internet for you, returning the information they find in a user friendly package. This is the next step forward for the internet.
The semantic web is already here. MusicBrainz has an extensive interface for software that wants to access it. Amazon.com also provides an interface to its databases for machines - this is how the present (somewhat limited) interaction between MusicBrainz and Amazon takes place. But hopefully, soon, more and more databases will be set up on the internet to provide this information. Eventually, users will actively demand that the websites they use work this way.
There's lots of technical details of course: standards like RDF and RSS, SOAP, "Service Oriented Architectures", and a whole lot more. But in a sense the details don't matter. The really important thing that's changing is a shift in attitude: from "this database is our property" to "this database is something we offer to the web as a service". This same shift has already been dealt with for "ordinary" content: everyone knows that if you publish a web page on the internet, anyone can read it; therefore, although it may technically be your property, you've already lost almost all control over it. This was a big leap for a lot of information providers, but we're slowly getting over it. A similar process of adjustment is in store for people who provide online databases, but until now those databases have only been available through their own, carefully controlled websites. Soon, data will flow to where it's needed most, and provided in the format that is needed most. And as with the web, we'll all be just that little bit better off for it.